LibreDataHub is a complete, self-hosted platform dedicated to data science and artificial intelligence. It aims to make modern data analysis tools accessible to small and medium-sized organisations, while offering a level of security and governance comparable to that of large institutions.
Developed by the InterHop association, the project brings together a suite of open-source tools for data management and analysis, statistics, machine learning and data warehousing — all deployable on a standard Linux server.
LibreDataHub is deployed in hospitals and tested in master’s programmes in data science (Lille, Paris 8). A non-HDS version is available for demonstration without installation, while a certified HDS version is available on request via InterHop servers.
LibreDataHub stands out thanks to its preconfigured, persistent environments, its native support for AI/ML workflows, and its project-centric security model. Database access is harmonised across all applications (Jupyter, RStudio, Code-server and CloudBeaver). Notebooks can be transformed into dashboards using MyST, and data is protected by robust backup strategies. Finally, installation remains deliberately simple through Docker Compose, without relying on complex orchestration tools.
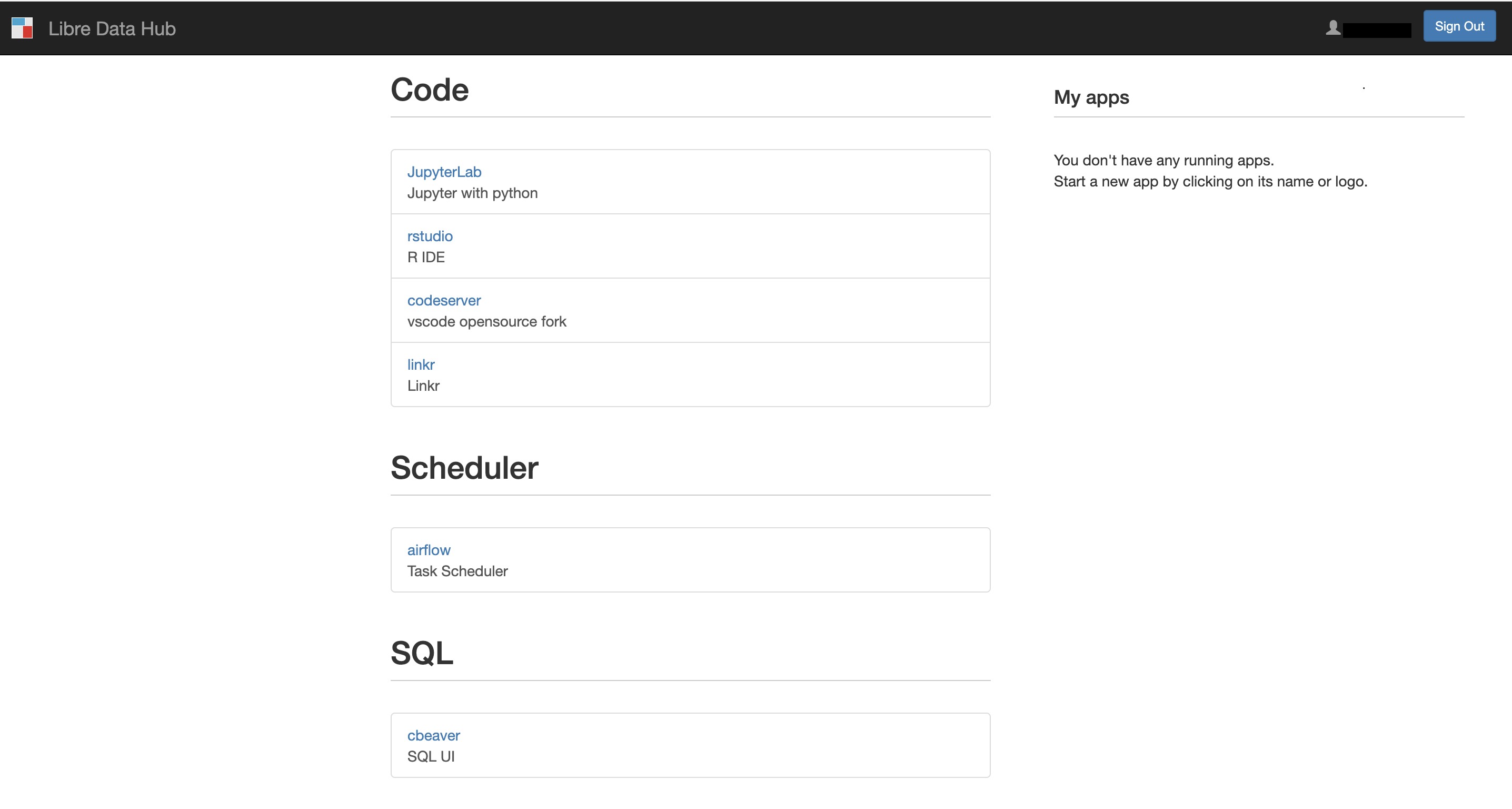
The main services include Jupyter, RStudio, Code-server, CloudBeaver and MyST. The monitoring stack uses Grafana/Prometheus, Airflow is used for orchestration, and Ollama for local LLM execution. For data persistence, we use PostgreSQL/Citus, DuckDB support, and an external S3-compatible storage for backups.
The whole system is guided by a few principles: efficiency on a single server, project-level isolation, unified database access and intelligent resource sharing.
Development is active and many enhancements are planned. The user interface will be expanded (improved home page, advanced file management, project dashboards). New tools are planned: Marimo, Dash, OnlyOffice, Draw.io, Gitea/GitLab, Superset and OpenWebUI. Support for additional databases (Solr, Neo4J) is being considered, along with more advanced resource management, encrypted backups and better observability.
Specific features are planned for education (virtual classrooms, automated testing, Git-based learning workflows) and for research (signal analysis, federation between LDH instances, advanced file management, project dashboards). Tighter integration with Goupile and LinkR is also underway.
Finally, LibreDataHub aligns with the requirements of the upcoming European Health Data Space (EHDS), positioning itself as a strong candidate for decentralised or even federated analytics.